CNN 架构基础概念
从输入层、卷积层、池化层到全连接层,梳理卷积神经网络(CNN)的整体架构与核心思想。
CNN架构的基础概念
CNN的整体架构主要分为四层:
- 输入层
- 卷积层
- 池化层
- 全连接层
输入层
接受原始数据,并以网络能够理解的形式,把数据输入到后续层
比如输入一张图片会转成三通道RGB到下一层中
卷积层(核心)
目的:尽量少的参数下,从局部到整体提取有用的特征,并保留空间结构, 高效地提取越来越抽象的特征。
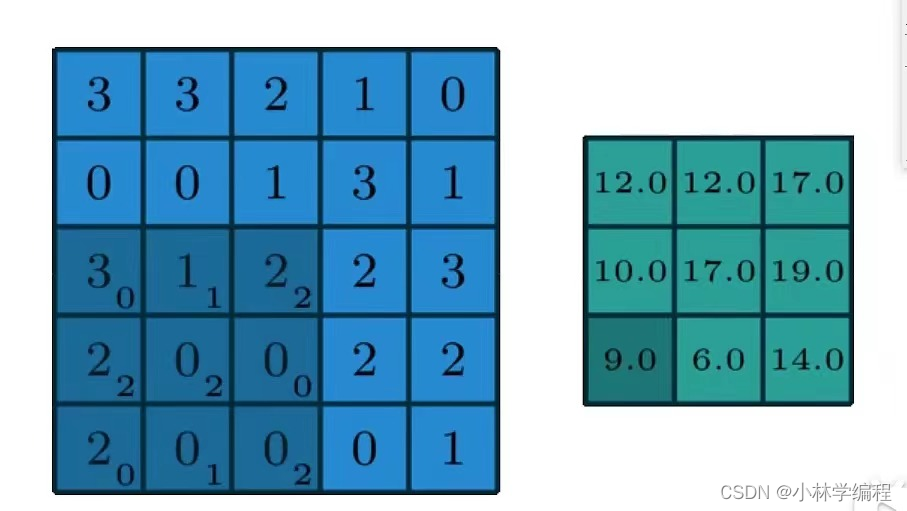
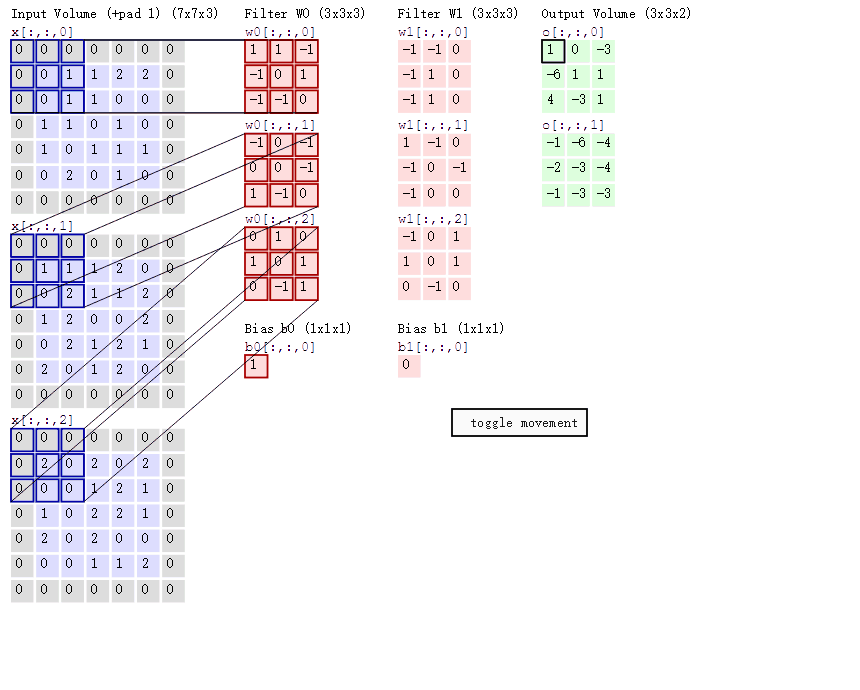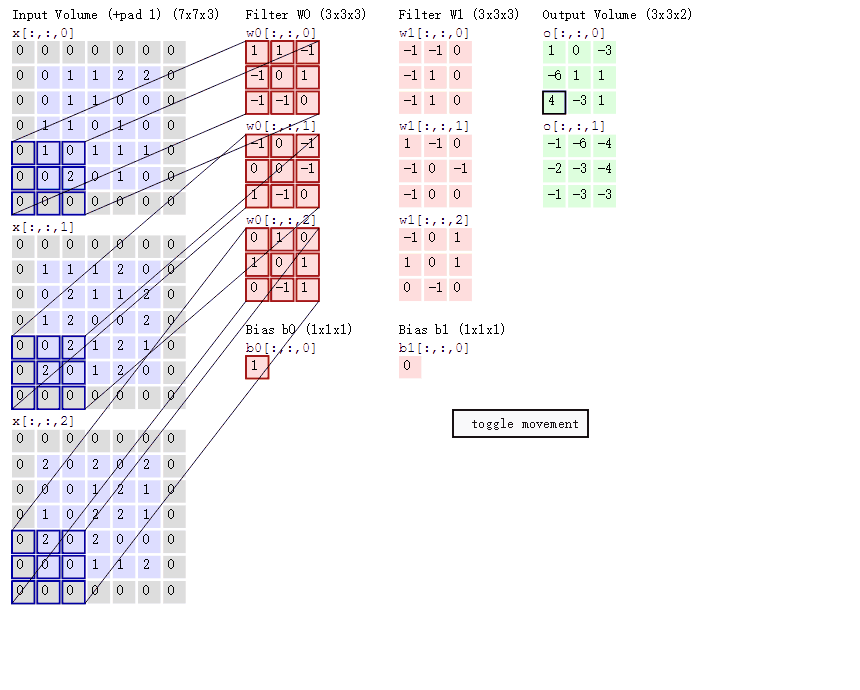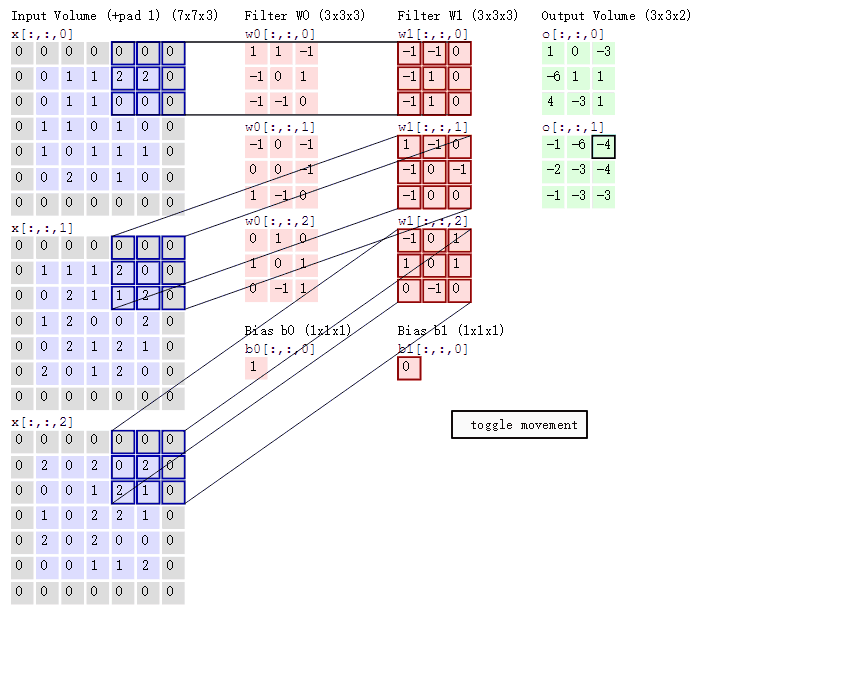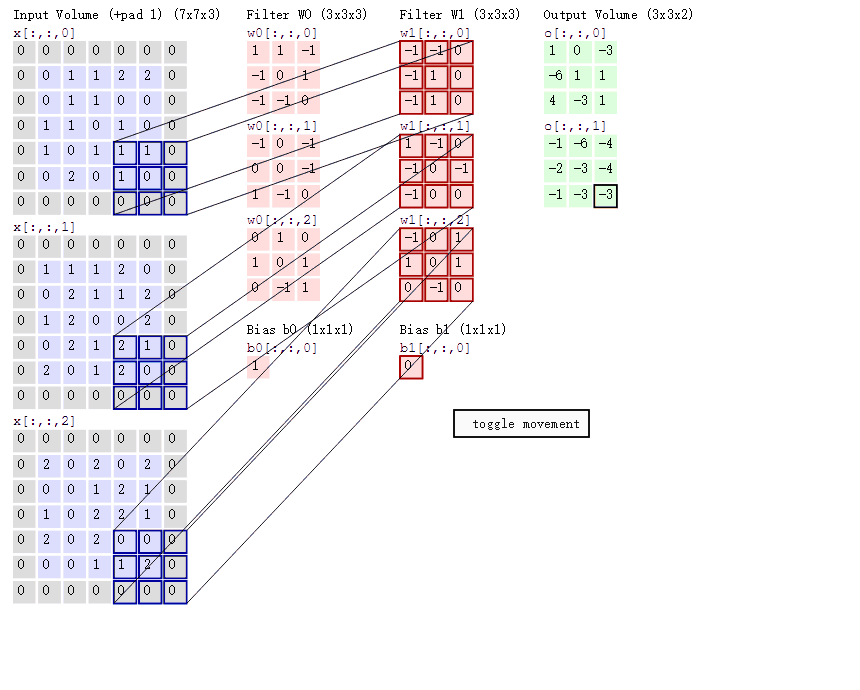
通过卷积核将特征提取出来,计算通过卷积核结果的过程如下:
计算过程
个人总结:
- 卷积层通过局部加权求和来提取特征,空间尺寸是否变小取决于 stride 和 padding(变小或者不变),但特征会更加突出
- 卷积核与输入局部区域越匹配,输出响应越大
- 每一层卷积的输出通道数 = 该层卷积核的个数
- ****每一个卷积核的通道数必须等于输入通道数
- 不同层的卷积核参数彼此独立
比如:一个图像是3通道的,卷积核个数为2,经过一层卷积之后矩阵变小,输出2通道;经过第二层卷积(卷积核个数为4)之后,会变成4通道的矩阵
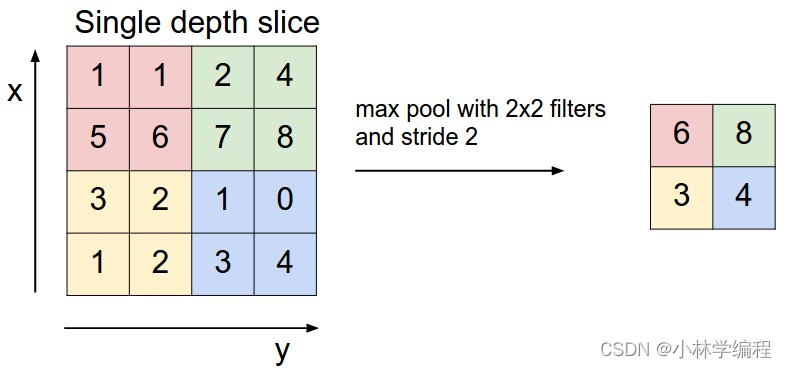
池化层
在尽量保证重要特征的前提下,降低空间分辨率,使特征更稳定、更高效,提高泛化能力
在一个区域内,选一个代表值(最大值 / 平均值)
全连接层
把前面的卷积/池化得到的高层特征综合起来,映射成最终任务需要的输出(类别、数值、概率)。
- 把“空间特征”变成“全局向量”
- 空间结构被打平,每个特征都参与最终判断
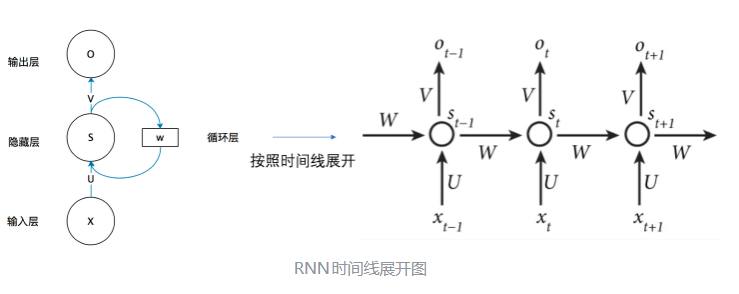
RNN架构的基础概念
主要是为了解决传统前馈神经网络无法有效建模“序列数据”和“时序依赖”的问题
前馈神经网络(CNN)有一个重要的假设
输入样本之间是相互独立的
但在很多真实世界任务中,这个假设不成立,例如:
- 语言:一句话中,后面的词依赖前面的词
- 时间序列:今天的股票价格依赖昨天、前天
- 语音:当前声音片段与前后片段相关
- 行为数据:用户当前行为受之前行为影响
也就是说 普通神经网络无法“记住过去的信息”
一句话说:
RNN 的出现是为了让神经网络具备“记忆能力”,从而能够建模序列数据中时序依赖和上下文信息,这是传统前馈神经网络无法做到的。
原理图
Transformer 架构的基础概念
自注意力机制
核心思想:在大量的信息,动态地“关注”最重要的部分,并根据相关词性进行加权汇总
自注意力机制中有三个重要的概念:
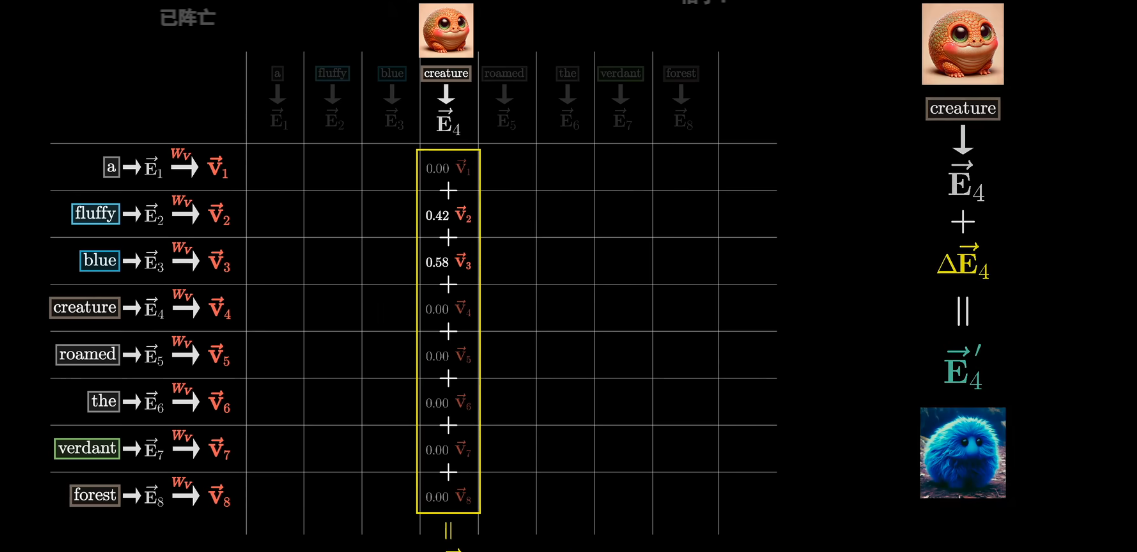
例子:一个毛茸茸的蓝色生物漫步于葱郁的森林中
- Query:
- 当前 token 想从“上下文”中找什么信息
- 例如“生物”的 Query 可能隐含地编码为:
- “修饰我的属性是什么?”
- “有没有和我相关的形容信息?”
- 词向量 * 可学习参数矩阵(Wq)
- Key:
- 每个 token「我能提供什么信息」的向量表示
- “蓝色” 的 Key 向量
- “毛茸茸” 的 Key 向量
- “生物” 的 Key 向量
- 每个 token「我能提供什么信息」的向量表示
都会被拿来 和 Query 做匹配
- 词向量 * 可学习参数矩阵(Qk)- Value:
- 当前分词与各个分词中的匹配的内容
- 词向量 * 可学习参数矩阵(Wv)
Query:我想要什么信息
Key:我能提供什么信息
Value:具体的信息内容
**Query × Key = Attention 权重→ 决定我关注谁
**Attention 权重 × Value → 决定我拿走什么
总结: 自注意力机制会对一句话进行分词和向量化,在处理每一个词时,**动态计算 **它与句子中其他词的相关性,并通过 **加权求和 **形成上下文表示,从而影响最终的输出结果。
重点: 自注意力机制不是给“一句话里的词”打一个固定权重,而是:在生成或理解每一个词时,动态计算“这个词应该重点看这句话里的哪些词”。
多头注意力机制
从多角度去理解一句话
例如:
- 一个头关注 语法关系
- 一个头关注 指代
- 一个头关注 距离很远但语义相关的词
transformer 架构原理
如果把数据想象成工厂的流水线,过程如下:
- 原材料入库:文字 -> 向量 + 位置
- 加工车间(Encoder):分析句内逻辑,每个词都带上整句话的背景
- 调度中心(Decoder):根据已生成的内容,并对照加工好的“背景”,决定下一个零件是什么。
- 成品出厂(Output):概率 -> 选定单词
第一阶段:输入预处理(Input Preprocessing)
- 分词:将输入的句子拆分成 Token
- 词嵌入:通过** 查找表(嵌入模型) **将每个 Token 转换成一个高维向量(例如 512 维)
- 位置编码:由于 Transformer 摒弃了循环神经网路(RNN),无法感知顺序。因此,需要将位置信息叠加到词向量中,让模型知道词与词之间的先后顺序
第二阶段:编码器处理(The Encoder)
编码器的任务是“理解”输入序列,一个编码器栈通常由 N 个相同的层堆叠而成。每一层包含以下步骤:
- 多头自注意力机制
- 计算Q,K,V:将输入向量分别乘以三个权重矩阵得到查询(Query)、键(Key)和值 Value
- 计算得分:计算 Q 和 K 的内积,除以缩放因子,在通过 Softmax 得到注意力权重
- 加权求和:用权重对 V 进行加权,提取出当前词与其他词的相关性上下文。
- “多头”:并行执行多次上述操作,最后拼接起来,让模型能从不同角度(如语法、语义)观察信息。
- 残差连接与层归一化:将注意力层的输出与输入进行残差连接(防止梯度消失),并进行 Layer Normalization
- 前馈神经网络:对每个位置的向量独立进行两次线性变换,进一步提取特征
- 再次 Add & Norm:重复残差连接和归一化
第三阶段:解码器处理(The Decoder)
编码的的任务是“生成”目标序列。它也是由 N 层组成,每层比编码器多一个步骤:
- 掩码多头自注意力:
- 掩码:在预测当前词中,不能看到“未来”的词。因此通过掩码操作作将未来的信息遮盖。
- 编码器-解码器交叉注意力:
- 这是最关键的一步。Query来自解码器的上一步输出,而 Key 和 Value 来自编码器的最终输出。
- 这使得解码器在生成每个词的同时,都能“回顾”输入句子的关键信息。
- 前馈神经网络(FNN):与编码器中的结构一致。
- Add & Norm:在上述每一个子层都会执行。
第四阶段:输出映射(Output Layer)
解码器的输出是一个连续的向量,需要将其变回具体的词:
- 线性层:将向量映射到一个巨大的维度,这个维度等于词表的大小。
- Softmax:将线性层的输出转化为概率分布。
- 获取预测词:
- **训练阶段:**计算预测概率与真实词之间的交叉熵损失。
- 推理阶段:选取概率最大的词,或者通过 Beam Search (束搜索)等策略选取最优路径。
RAG基础
MCP协议
这个是由 Anthropic 公司在2024年底推出的一个开源标准协议。
- 为什么需要MCP?
在mcp出现之前,如果你想让 AI 模型读取你的本地文件、查询数据库或者调用 Slack、Google、Drive 等工具,每个开发者需要为每种工具编写定制化的连接代码。
- 痛点:数据分散在各种应用和数据库中,AI 难以通过统一的方式安全的获取这些上下文。
- 现状:由于缺乏标准,集成工作会非常繁琐,且难以跨越模型和工具复用
- 什么是MCP?
mcp 是AI 的“USB 接口”标准
就像 USB 出现之前,打印机、鼠标、键盘需要各种不同的接口,而 USB 统一了硬件连接方式一样; MCP 旨在统一AI模型与外部数据/工具之间的连接方式
Function call
Function Call 是大语言模型(如:GPT-4,Claude3.5)的一种原生能力。它允许模型在识别到用户意图时,不直接返回一段文字,而是输出一个结构化的数据(通常是 JSON),告诉外部程序:“我需要你帮我运行这个函数,参数是 X。
MCP 与 Function Call 的关联
在MCP架构中,“Tool(工具)”这个核心概念本质上就是 Function Call。但 MCP 对其进行了升级:
- 包含关系:MCP 使用了 Function Call 的技术来实现“工具执行”的功能
- 统一封装: MCP 协议规范了 Function Call 的请求和响应格式,使得不同的 AI 客户端(Host)和不同的工具(Server)可以无缝对接。
形象的比喻
- Function Call 是“具体的电器插头”:
如果你买了一个戴森吸尘器,它的插头是特制的。你想用它,必须在家里专门装一个戴森的插座。如果你换成了米家吸尘器,可能又要换插座(这就是为每个模型写定制代码)。 - MCP 是“国标墙插/插线板”:
它规定了插座的形状、电压和电流。不管你是戴森、米家还是海尔(不同的模型/工具),只要大家符合这个国标(MCP),买回来直接插上就能用